What is up? It’s hot over here.
I have had the pleasure of flying with three European budget airlines this summer.
A few weeks ago, I wrote about the Ryanair check-in experience. It was exactly the dark pattern UX hellscape that I dreamed of – a true education and delight.
I’ve now also flown with easyJet and Wizz Air (named after the cheese?) and so I am able to impartially and scientifically present a head-to-head-to-head showdown: who has the worst and most misleading UX?
Ryanair

It’s Ryanair. Ryanair are the worst. Maybe the article would be “better” if I saved the reveal for the end, but, whatever, like there could be any other victor.
Ryanair gets 10 / 10 golden harps for a long, confusing and actively misleading check-in flow. Can the others even get close?
Wizz Air

A disappointingly non-confrontational experience, where you just say no, I don’t want that, and the site just kind of agrees and goes along with it? And then some stuff about who are you, no explosives, thank you, I’ve already eaten, and that’s it.
Wizz Air gets an initial 2 / 10 golden harps for the standard-issue presence of random seat and insurance/hotel/car up-sell features.
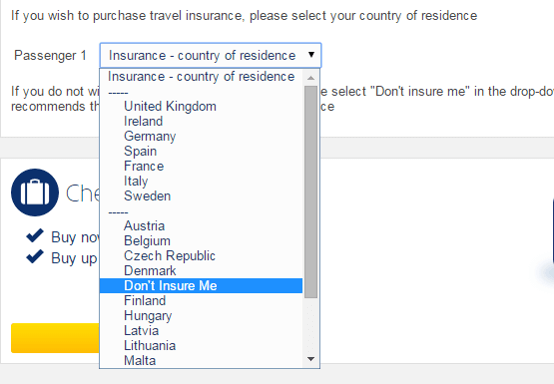
They are awarded an additional bonus 2 golden harps, a grand total of 4 / 10 golden harps, for this shocking date selection widget. It’s shown here picking dates for a flight but they use the same one for your date of birth. See how it is impossible to type in a date, and it’s very difficult to discover how to change year without scrolling month-by-month, potentially for decades…
Interlude: the curse of the apostrophe
Anyone with an apostrophe in their name – or names that otherwise do not conform to narrow cultural expectations or that break bad/legacy code/integrations – will understand this.
I booked these trips through booking.com. Overall, a good experience, except I couldn’t get Wizz to recognise my name. I tried to resolve this via both Booking.com and Wizz Air support, and in fairness both did respond quickly with the information I needed, which was to use one of the usual fallbacks of O space SULLIVAN. I did however have to lie to a phone menu to talk to a Wizz Air human, who was clearly evaluated on call time, and couldn’t wait to get rid of me…
EasyJet

EasyJet are similarly un-Ryanair-y and seem to have forgotten to squeeze you hard. The seat / bag stuff isn’t particularly alarmist, with only a small amount of “are you sure?”. There is one interstitial about like buying a sandwich, and the up-sell items are easy to overlook and actually come after check-in is complete.
Both Wizz Air and EasyJet also provide a good-ole PDF boarding pass, which worked fine on my phone without an airline app, unlike Ryanair who have removed this option.
3 / 10 golden harps. Do they actually recognise their customer as a sentient being, deserving of respect, or something? Must try harder.

On check-in strategy
As mentioned last time, I generally try to check-in with “random” seat allocation immediately before the flight, the logic being that if they’ve already given away the “bad” seats they’ll be forced to give you a “good” one.
This time round, I wasn’t able to check-in at the last moment, but in both cases it was on the day of the flight. Wizz did what you expect and gave me a middle seat near the back, boo hoo. EasyJet, on the other hand, gave me an aisle seat in the exit row – one of the best and most expensive seats on the plane.
Of course, if you pay for a middling known-quantity seat, your chance of getting a top one is exactly zero. You can’t win if you don’t play.