Hello friends!
Today I’m presenting the database configuration that I (currently) use on pythondocs.xyz – real time interactive search of Python documentation.
It copies a SQLite database from disk into memory, so it’s very fast. It’s great for read-only workflows – dashboards and the like. It’s not suitable for sites that accept user input, as it makes no attempt to preserve updates to the database.
The config works well for pythondocs.xyz: I generate the site’s database “offline”, with a standalone parser application, and I ship the resulting database file with the web application. When the web app starts up, the database is copied into memory, and you get nice fast database access (even if your queries aren’t super efficient!)
The main dependencies are sqlalchemy, the predominant Python ORM, and aiosqlite, an async replacement for the Standard Library’s sqlite3. I use the database with FastAPI but it should work in other applications.
The database copying is handled by sqlite3‘s backup method. But sqlite3 is a synchronous library, and I want concurrent database access for performance reasons. Luckily, it’s possible to populate the database with sqlite3 and read it from aiosqlite by pointing the two libraries at the same shared memory location.
Without further ado, here’s the code that sets up the database:
from typing import Optional
from sqlalchemy.engine import Engine, create_engine
from sqlalchemy.ext.asyncio import AsyncEngine, AsyncSession, create_async_engine
from sqlalchemy.orm import sessionmaker
SQLITE_SYNC_URL_PREFIX = "sqlite:///"
SQLITE_ASYNC_URL_PREFIX = "sqlite+aiosqlite:///"
MEMORY_LOCATION_START = "file:"
MEMORY_LOCATION_END = "?mode=memory&cache=shared&uri=true"
class InMemoryDatabase:
"""
Async in-memory SQLite DB
"""
def __init__(self, sql_echo: bool = False):
self.sql_echo = sql_echo
self._sync_memory_engine: Optional[Engine] = None
self._async_memory_engine: Optional[AsyncEngine] = None
self._async_sessionmaker: Optional[sessionmaker] = None
def setup(self, filename: str):
"""
Copy DB data from disk to memory and setup async session
"""
sync_disk_engine = create_engine(
url=SQLITE_SYNC_URL_PREFIX + filename, echo=self.sql_echo
)
in_memory_url = MEMORY_LOCATION_START + filename + MEMORY_LOCATION_END
# Reference to sync in-memory engine remains open
self._sync_memory_engine = create_engine(
url=SQLITE_SYNC_URL_PREFIX + in_memory_url, echo=self.sql_echo
)
# Use sync engines to copy DB to memory
backup_db(source_db=sync_disk_engine, target_db=self._sync_memory_engine)
sync_disk_engine.dispose()
# Create async engine at same memory location
self._async_memory_engine = create_async_engine(
url=SQLITE_ASYNC_URL_PREFIX + in_memory_url, echo=self.sql_echo
)
self._async_sessionmaker = sessionmaker(
self._async_memory_engine, class_=AsyncSession
)
Compatibility with FastAPI’s dependency injection is provided by this method:
async def __call__(self) -> AsyncIterator[AsyncSession]:
"""Used by FastAPI Depends"""
assert self._async_sessionmaker, "No sessionmaker. Run setup() first."
async with self._async_sessionmaker() as session:
yield session
(Thank you to the FastAPI Pagination project for inspiration!)
Use with FastAPI looks like this:
from fastapi import Depends, FastAPI
from sqlalchemy import select
from sqlalchemy.ext.asyncio import AsyncSession
from async_in_memory_db import InMemoryDatabase
from example_data import DB_FILENAME, User
app = FastAPI()
db = InMemoryDatabase()
@app.on_event("startup")
async def setup_db():
db.setup(DB_FILENAME)
@app.get("/")
async def example_route(session: AsyncSession = Depends(db)) -> list[User]:
results = await session.execute(select(User))
return results.scalars().all()
And here’s what you get in your web browser:
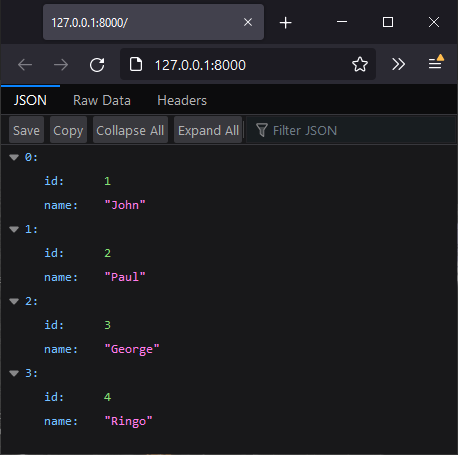
Please see the python_async_in_memory_db GitHub repo for the full code, including an example standalone query that doesn’t use FastAPI.
Is this technique useful to you? Can you see any potential pitfalls that I’ve overlooked?
Let me know in the comments below!